top of page

レジリエンスンジニアリング
-
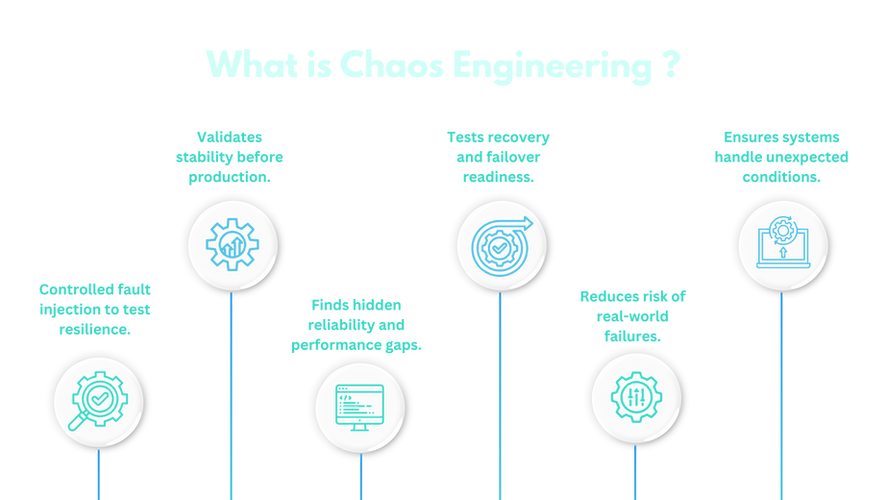
Orchestrated fault injection using Chaos Mesh to simulate network partitions, DNS failures, and pod-level instability across Kubernetes-native environments.
-
Silicon-to-Software reliability audits injecting resource exhaustion (CPU/Memory stress) and I/O latency to validate hardware-level bottlenecks and failover logic.
-
Automated SLO validation and blast radius analysis correlating chaos experiments with Prometheus/Grafana metrics to identify recovery gaps in distributed microservices.
-
MTTR optimization and robustness benchmarking to evaluate the trade-offs between cloud redundancy, system performance at scale, and infrastructure spend.
bottom of page